Hash functions
Entradas registradas para este tema:
¿Qué diferencia hay entre SSH y MD5?
Esta pregunta no tiene mucho sentido; enseguida me di cuenta de ello. Uno es un protocolo para establecer comunicación segura sobre redes inseguras y el otro una función hash.
Entonces lo siguiente era averiguar: ¿Qué es una función hash?¿Cuál es su utilidad en InfoSec? ¿Cómo se construye?, ¿Cuáles son sus vulnerabilidades?
¿Qué es (y qué no es) un hash?
Definición: Una función hash toma un input de longitud arbitraria n y devuelve un output de longitud fija m. Esa es la propiedad de compresión; además, debe ser de fácil computación.
Podemos dividirlo en:
- Keyed hash functions: Tienen como input el mensaje y una clave (los MAC).
- Unkeyed: Solo el mensaje (como los MDC - Modification Detection Code)
En este post nos centraremos en el comportamiento de las unkeyed. En próximos posts veremos cómo se comporta una función MAC o HMAC en el contexto de un protocolo SSH.
No hay que confundir una función hash con un cifrador.
Un cifrador quiere que el receptor del mensaje sea capaz de descifrar el mensaje original. Su objetivo es la confidencialidad.
La función hash no es invertible, eso es lo que la hace segura, como veremos más adelante. Un hash quiere que el receptor sepa si el mensaje ha sido alterado.
Este es el concepto de integridad y autenticidad. Forman, junto con la confidencialidad, los pilares de la seguridad de la información.
Piénsalo: un cifrador nos asegura la confidencialidad desde el momento en que el mensaje que genera el emisor, al cifrarlo, impide que cualquier tercero vea su contenido. Pero si pudiera modificarlo, aunque no lo viera, nosotros al desencriptarlo no lo sabríamos. O peor aún, si sustituye el mensaje original por uno del atacante y lo cifra de la misma manera, no tendríamos forma de saberlo sin un mecanismo de autenticación.
Esto responde a la cuestión: ¿No sirve por sí sola la encriptación para tener integridad y autenticación?
En la misma situación, imaginemos que emisor y receptor han establecido una regla: cada mensaje irá firmado con el total de letras x 3 x la suma de la fecha en que se emitió (no es una regla muy complicada de adivinar, pero nos sirve de ejemplo).
En ese caso, si un atacante sustituye alguna palabra, la borra o directamente cambia el mensaje, él no sabe de dónde viene ese número creado por nuestra regla inventada. Al recibir el mensaje y verificar la regla, veríamos que no cuadra y es señal de que han modificado el mensaje y no es auténtico.
Entonces estamos de acuerdo en que establecer un sistema para preservar la integridad y la autenticidad es importante. Pero, ¿qué hace a una buena regla? En otras palabras:
¿Qué significa que una función hash es segura?
Para ello he de introducir dos conceptos: resistencia a la preimagen y resistencia a colisiones.
Si somos un atacante más o menos perspicaz, aunque no sepa la regla que hemos inventado, se dará cuenta observando los mensajes o simplemente, si tiene acceso al sistema, que cambiando una letra por otra no modifica el número identificador; puede encontrar varios mensajes con el mismo "hash". Nuestra función fallaría todas las propiedades.
-
Resistencia a la primera preimagen (First-preimage resistance): Querriamos que, dado un hash H, el atacante no pueda encontrar un mensaje que genere ese mismo hash H. Este tipo de funciones también se llaman en inglés one-way functions.
-
Resistencia a la segunda preimagen (Second-preimage resistance): Dado un mensaje M1 con hash H1, debe ser prácticamente imposible encontrar M2 que genere el mismo hash H1. Démonos cuenta de que si no se cumple la primera, no puede cumplirse la segunda.
-
Resistencia a colisiones (Collision resistance): Debe ser casi imposible encontrar M1 y M2 tales que $h(M1)=h(M2)=H$; es decir, encontrar dos mensajes cualesquiera con el mismo hash. De nuevo, si se cumple esta, se cumple la resistencia a la segunda preimagen.
Si te cuesta ver la diferencia entre estas propiedades, piensa en la función $g(x)=x^{2}$ $mod$ $3$.
Esta función es first-preimage resistance, ya que dado $g(x)=0$, no sabemos qué mensaje x lo ha generado (sabemos muchos: 3,6,9... pero no cuál en particular).
Sin embargo, no cumple la segunda porque dado $g(2)=1$, sabemos otro mensaje $g(4)=1$ con el mismo hash. Y, por supuesto, en ese caso también puedes encontrar colisiones.
Vale, ¿y por qué decimos que debe ser "prácticamente imposible"? ¿Por qué no aspiramos a lo máximo y que sea imposible?
Bueno, por las palomas. Si tenemos 10 palomas y 9 jaulas, una jaula tendrá 2 palomas. Eso tiene lógica. Como los posibles mensajes son infinitos y los hashes son finitos. las colisiones existen.
Lo que queremos es que el número de combinacionessea tan absurdamente alto que, el atacante tendría que probar miles de años para encontrar dos mensajes que van al mismo hash. Por eso una forma simple de aumentar la seguridad sería aumentar las combinaciones. Aunque no basta con eso, debe ser matemáticamente complicado poder mandar dos "palomas" a la misma jaula.
-
Una función hash MD5 (1992) tiene una salida de 128 bits, es decir, $2^{128}$ combinaciones.
-
Una SHA-1 (1995) son 160 bits.
-
Las utilizadas hoy en día, SHA-256 o 512, tienen $2^{256}$ o $2^{512}$ combinaciones.
Este numerito para $2^{256}$ es:
115,792,089,237,316,195,423,570,985,008,687,907,853,269,984,665,640,564,039,457,584,007,913,129,639,936
¿Pero por qué hace falta tantas combinaciones? ¿No es suficiente con $2^{128}$? respuesta corta, NO y sería posible gracias al Ataque del Cumpleaños (o en inglés, que suena más guapo, Birthday Attack).
La idea es que para encontrar dos colisiones cualesquiera tienes $\frac{N×(N−1)}{2}$ pares de posibilidades. Es decir, para MD5, nos bastaría con realizar $2^{64}$ operaciones de media para encontrar una coincidencia.
Además de estas propiedades, querremos por construcción que nuestra función parezca aleatoria. Que sea impredecible. Esto lo podemos ver como el efecto avalancha: un cambio pequeño genera un resultado totalmente distinto. Lo podemos ver en este ejemplo donde os muestro cómo dos letras con solo un bit de diferencia generan hashes totalmente distintos.
Por ejemplo, MD5 devuelve 32 caracteres hexadecimales (128 bits).

Esta es la diferencia entre su representación en hexadecimal y, para ver que efectivamente la salida es 128 bits:

Entonces, ¿de dónde surge el efecto avalancha? ¿Por construcción o es consecuencia de las otras propiedades? ¿Hacen falta siempre las tres propiedades? ¿Cómo se combinan la encriptación y las funciones hash?
¿Cómo construimos funciones hash?
Desde 1980 se utiliza la arquitectura Merkle-Damgård, que consta de un proceso iterativo de funciones de compresión, dividimos un input grande en bloques pequeños, generalmente de 512 bits. Donde H0 se llama vector de inicialización y dividimos los bloques de 512 en pedazos de 32 bits que forman los $M_i$.
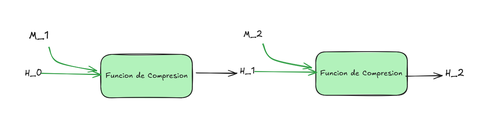
¿Y si tenemos un mensaje con menos bits o con más? Ahí es cuando utilizamos la técnica de padding, que en resumidas cuentas es añadir ceros. En nuestro ejemplo del carácter "a", tenemos el mensaje de 8 bits 01100001; tenemos que concatenarle 504 bits de la forma 01100001 || 100000...000 1000. El último 1000 (23) indica el tamaño del mensaje: los 8 bits de la "a".
Claro, viéndolo así, a mí me surge el pensamiento: ¿Cómo se va a diferenciar el hash de poner como input "a" o "b" si son tan parecidos y los restantes 504 bits los estás rellenando con padding? Aquí entra en juego la construcción del algoritmo de compresión. Veamos por encima el MD5:
Consta de 64 rondas. Se usan funciones lógicas, rotaciones de bits y constantes basadas en el Seno. Cada ronda "mezcla" los bits de tal forma que el pequeño cambio inicial se expande por todo el resultado. Las pequeñas diferencias se van agrandando conforme pasan las rondas del algoritmo. Esto es lo que causa el efecto avalancha y que sea impredecible.
De hecho la demostracion que enterro MD5 fue un ataque con el objetivo de minimizar las diferencias en cada ronda del algoritmo. En este paper demostraron que podian encontrar colisiones con $2^{39}$ operaciones, menos de una hora con un ordenador usual.
Esa investigacion fue clave para evolucionar a funciones hash mas seguras. De hecho, preocupados porque SHA-2 tenia una arquitectura similar se celebraron competiciones para mejorar o igular la seguridad, velocidad de hash SHA-2 pero con distinta arquitectura. De aqui salio SHA-3 o BLAKE.
Volviendo a nuestra pregunta original ¿Cómo afecta esto a SSH?
Veras que las fingerprints de las llaves ya no usan MD5, si no SHA-256 o algoritmos de curvas elipticas. En proximos post me parece muy interesante investigar que ocurre cuando añades una clave secreta, entraremos en territorio de los HMAC y como SSH orquesta todos estos elementos: cifrados, hashes y llaves para que puedas trabajar tranquilo.